Using Playgrounds
The Interface
Each playground is a set of columns. Each column runs one prompt configuration independently.
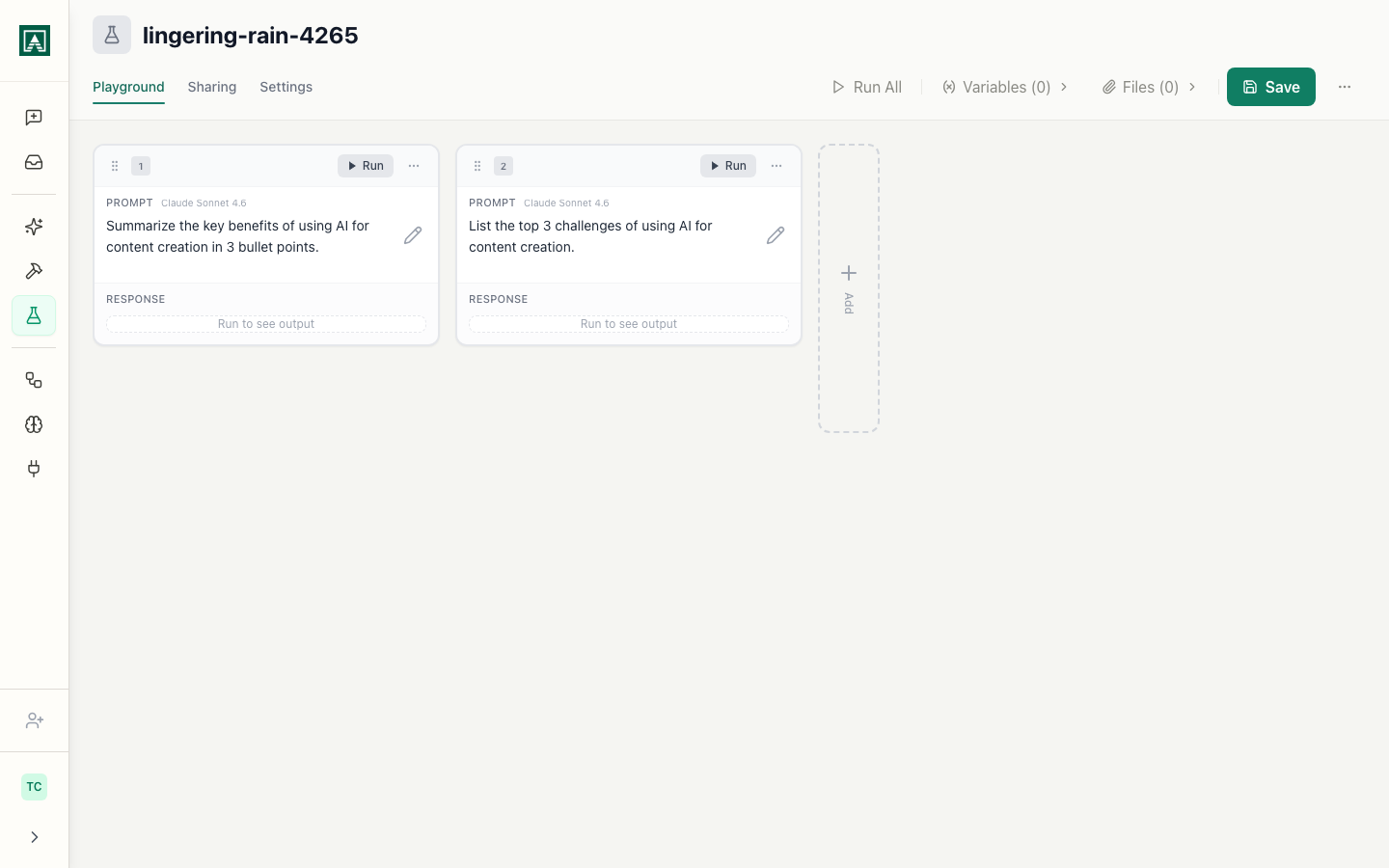
Column controls:
- Prompt selector - choose from your library or create a new prompt inline
- Version selector - pick which revision to load
- Model selector - override the prompt's default model
- Settings (gear icon) - temperature, max tokens
- Input fields - variable values for this column
Workspace controls:
- Add column - adds a new column to the right
- Run all - executes every column simultaneously with its current inputs
- Save - preserves the current state
Setting Up a Comparison
Different prompt versions
- Add two columns
- Load the same prompt in both
- Set one column to the current version, the other to a newer revision
- Enter the same input values in both
- Click Run all
Different models
- Load your prompt into a column
- Duplicate it into additional columns
- Change the model selector in each column
- Enter inputs and click Run all
Different settings
- Load the same prompt and model into multiple columns
- Adjust temperature or max tokens in each column independently
- Run all with identical inputs
Inputs
Input fields appear below each column header, one field per prompt variable. Enter values before running.
All columns share the same input values by default. You can override individual column inputs to test how a prompt handles different data.
Files can be uploaded per column if the prompt accepts file attachments.
Outputs
After running, each column displays its output below the input fields. Token usage and response time appear alongside each output.
Scroll down to read outputs. Long outputs are scrollable within the column.
Settings
Click the gear icon on any column to adjust:
| Setting | Description |
|---|---|
| Temperature | Controls output variability. Lower values (0.0–0.3) produce more consistent outputs. Higher values (0.7–1.0) produce more varied outputs. |
| Max tokens | Maximum response length. Lower values truncate long responses. |
Settings apply to that column only.
Versions
Every saved change to a prompt creates a new revision. The version selector in each column lets you choose which revision to load. Load two different revisions in separate columns to compare them directly.