LLMOps without the glue code
Version prompts, test across models, deploy to production, and monitor usage. One platform replaces fragmented tooling.
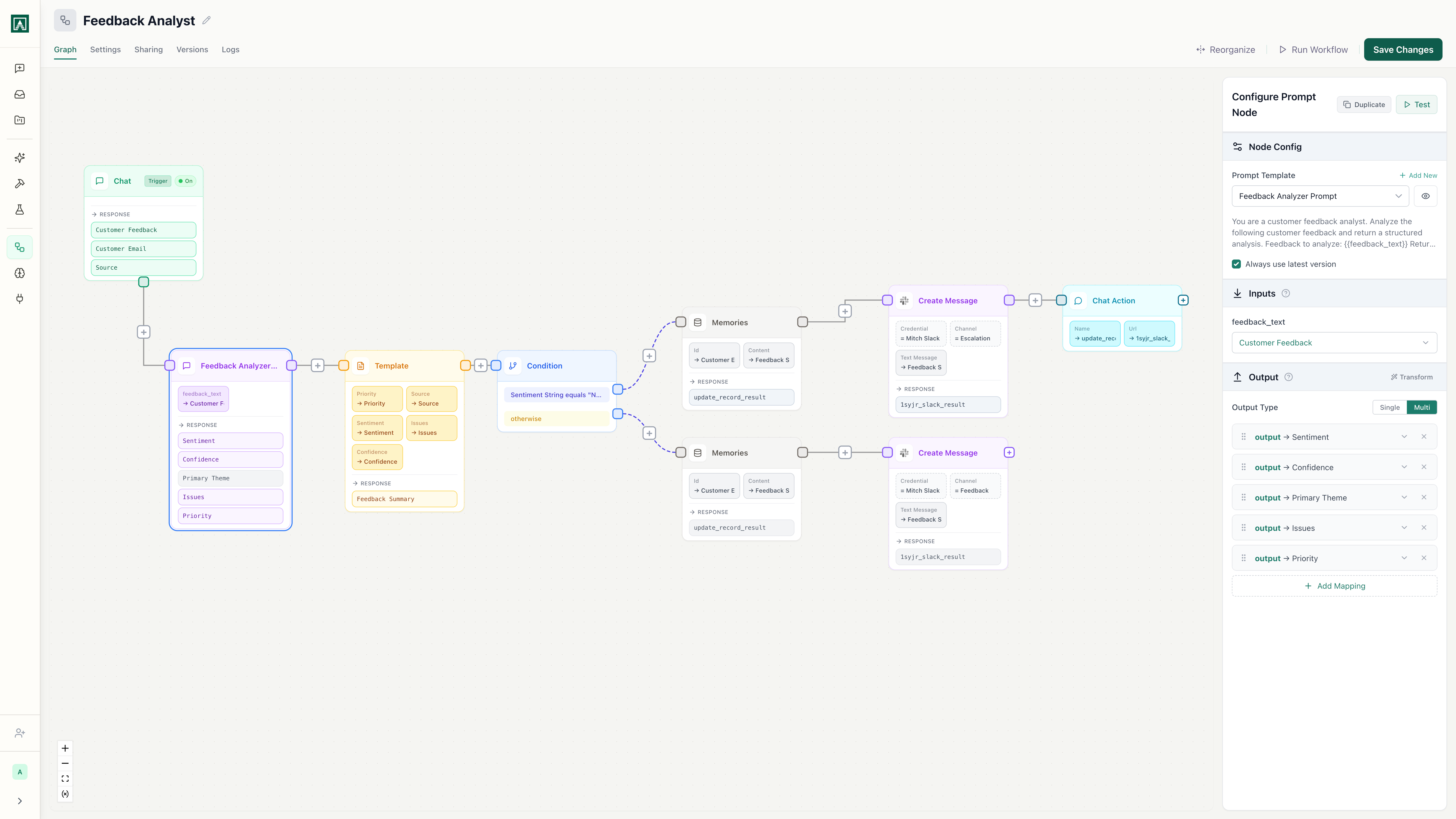
Customer Feedback Analyzer
v12 · Last edited 2 hours ago
Works with every model
 Anthropic
Anthropic OpenAI
OpenAI Gemini
Gemini xAI
xAI OpenRouter
OpenRouter Amazon
Amazon Perplexity
Perplexity MoonshotAI
MoonshotAI Meta
Meta Qwen
Qwen
What is LLMOps?
LLMOps (Large Language Model Operations) is the set of practices for managing the full lifecycle of LLM-powered applications: prompt engineering, version control, testing, deployment, and monitoring. It's MLOps for the age of foundation models.
Build
Author prompts with variables, structured outputs, and model settings in a visual editor.
Test
Compare prompt performance across models side-by-side in Playgrounds.
Deploy
Ship to chat, API endpoint, webhook, or scheduled trigger with one click.
Monitor
Track usage, costs, and team adoption across every prompt and workflow.
Every stage of the LLMOps lifecycle, in one platform
Prompt versioning and rollback
Every prompt edit creates a version. Diff any two versions side-by-side, see who changed what, and roll back with one click. No more grepping through git history to find what changed.
See it in actionModel-agnostic testing
Compare the same prompt across GPT-4, Claude, and Gemini simultaneously in Playgrounds. Find the best model for each task before you ship to production.
See it in actionWorkflow automation
Chain prompts, integrations, and logic into multi-step workflows. Trigger from webhooks, Slack, or schedules. Every workflow step can reference versioned prompts. Change a prompt once and every workflow using it gets the update.
See it in actionGovernance and monitoring
Role-based access control, audit logs, usage tracking, and model selection per team. Track costs, monitor adoption, and control who can do what.
See it in actionAutomate real work, not just demos
Build workflows that combine AI reasoning with your existing tools. Trigger from Slack, webhooks, or schedules.
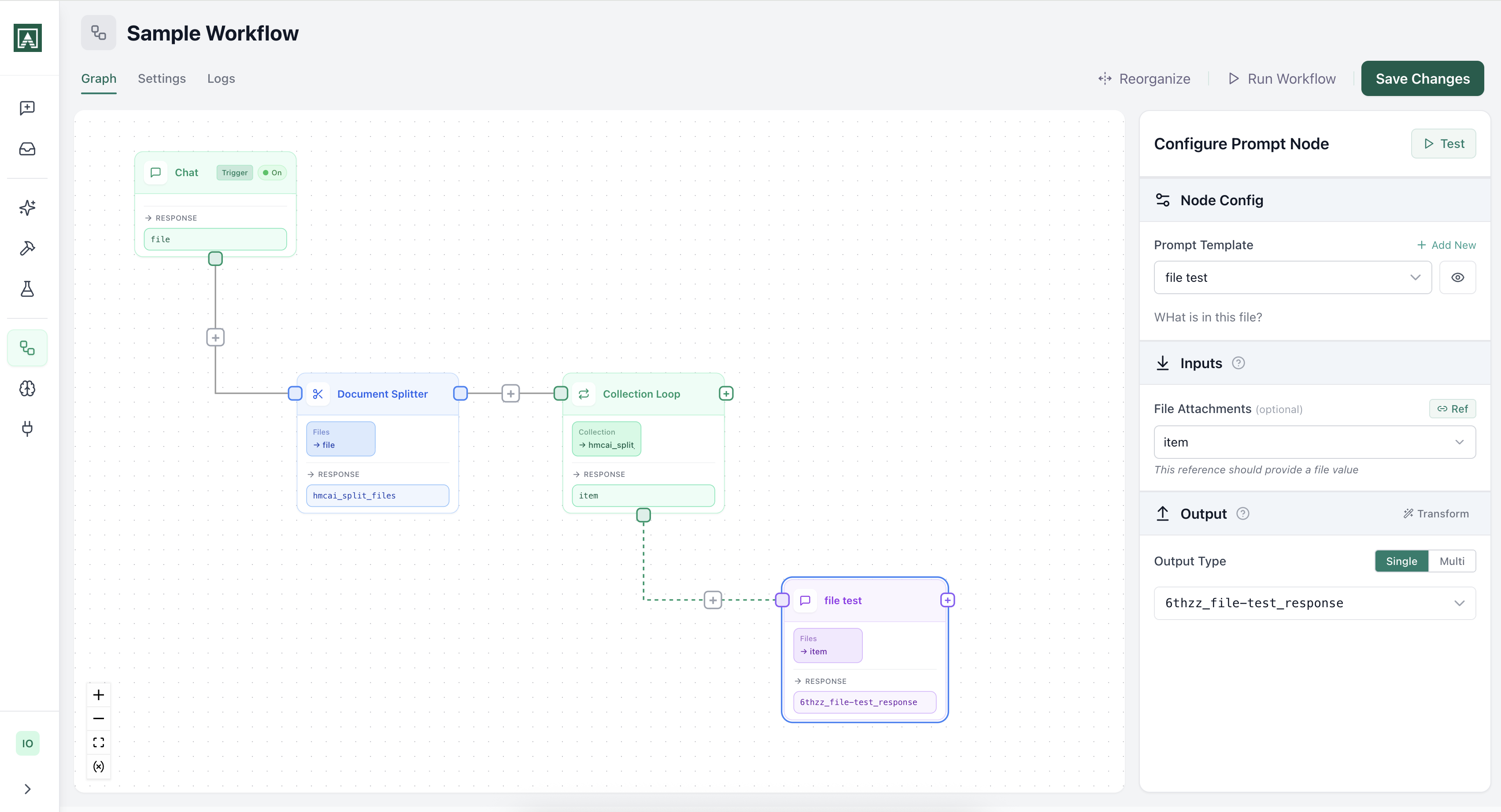
Classify and route incoming email
A prompt classifies email by intent and urgency. A condition node routes it to the right queue. The whole team can run it.
Connects to the tools you already use
Pull data from Slack, Google Drive, GitHub, and dozens more. Push results out and let AI coordinate across your stack.
LLMOps is simpler when everything is in one place.
Stop stitching together Langfuse for monitoring, LangSmith for testing, and custom scripts for deployment.