Last night I built an X agent on @aisle_sh that isn't a fire-and-forget bot. It drafts posts and replies, queues them for me to review, and once a week it proposes edits to its own instructions based on what I approve, reject, rewrite, or ignore. It starts in review-only and graduates to autonomous posting on specific topics once its approval rate clears a threshold I set.
Twelve hours later the loop runs end to end.
Quick note on what this is and isn't. The cleanest version of what we're building toward at Aisle is what I've been calling deterministic agents. A model picks from a set of bound tools and executes one. The model chooses; the tool runs a fixed action. The autonomy is in the picking. This build isn't quite that. It pushes the model into more of the reasoning than the strict version would. I built it to see how far the idea stretches, not to show where we think it lands.
What I came away wanting to write about is what happens to the pieces of a platform when they share state. A knowledge base holds my voice rules. A task reads them and writes a draft. I approve or reject it. Another task reads my decisions back and updates the voice rules. The review queue is also a training set. The components stop behaving like separate features.
I'll get to that. First, what I actually built.
What it does:

Six Python scripts, four steering docs, one Project that hosts the review chat. Every six hours a task drafts five candidate posts. Every few hours another searches X for threads worth replying to and drafts replies. Everything lands in a review chat where I approve, reject with a reason, edit, or defer. Once a week a third task reads the decisions back, finds patterns in what I rejected, and rewrites the agent's lessons note for next week.
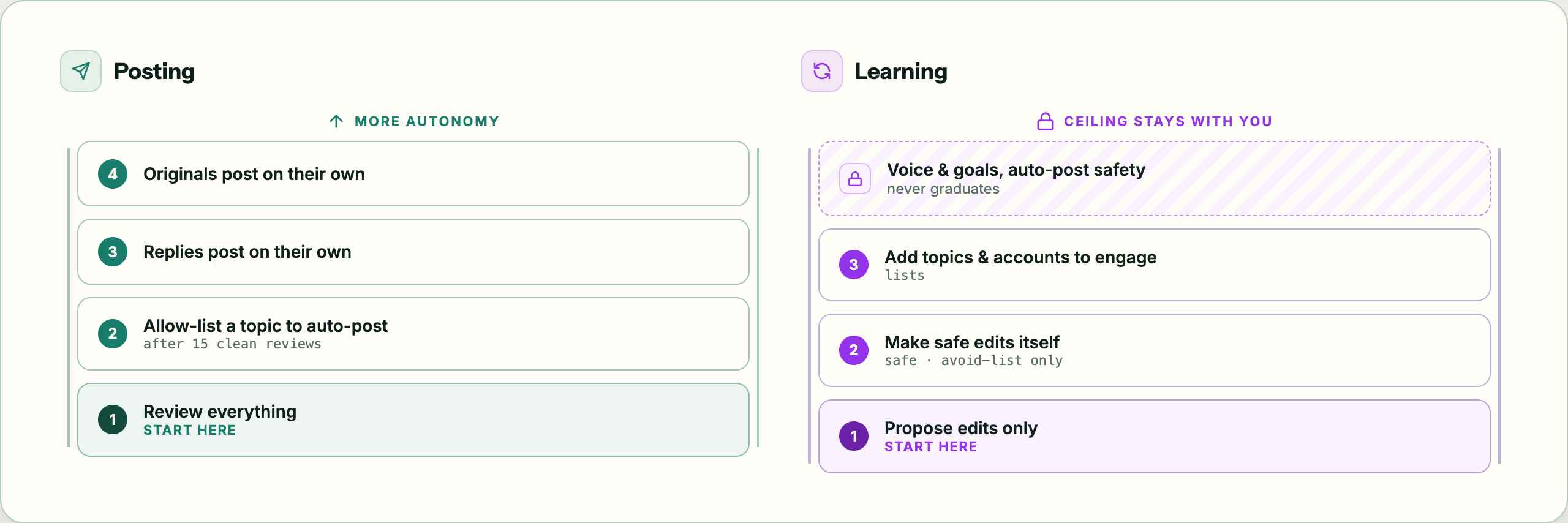
There's an autonomy ladder on top of it. Right now everything is review-only. I can promote a topic to auto-post once I've approved 15 drafts on it with a clean rejection record. The agent can make small additive changes to its own instructions on its own, like adding an account to an avoid list. The voice and goals docs stay mine.
Architecture:
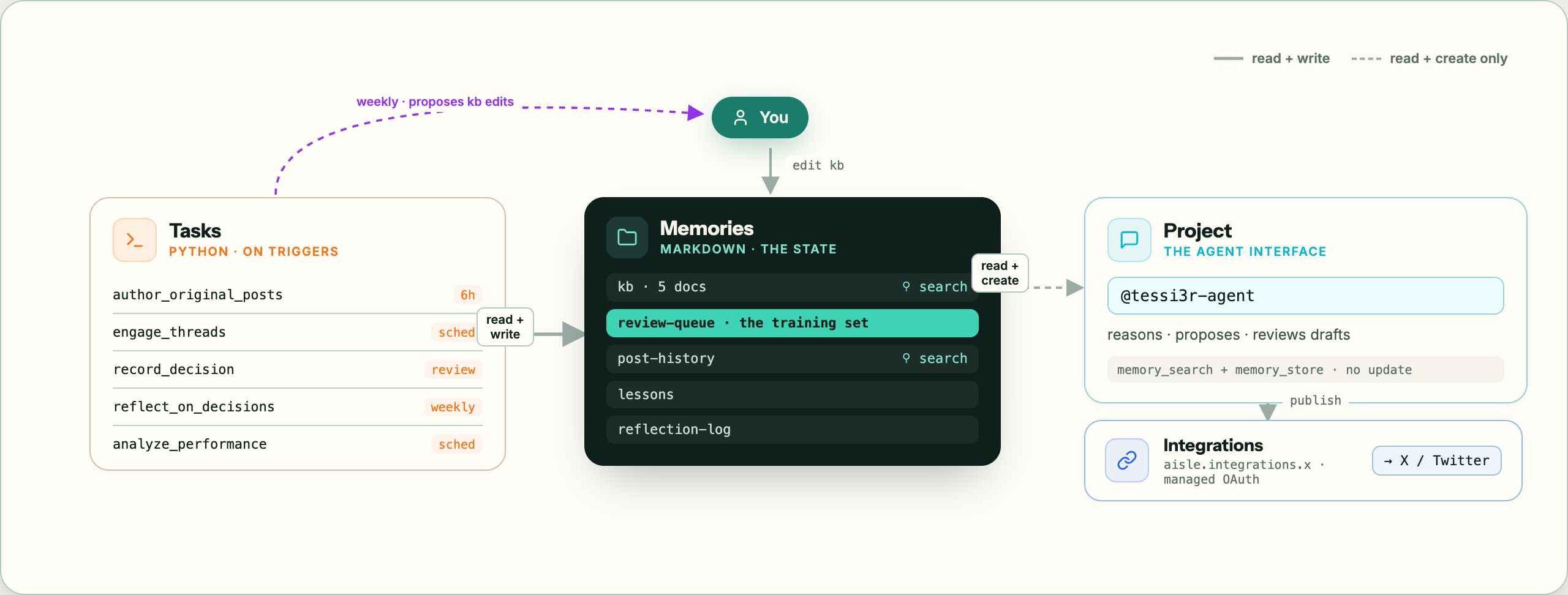
Four building blocks, all on Aisle.
- Tasks run on triggers and do the work. Single-file Python scripts.
- A Project as my daily agent interface. It has its own instructions, tools, knowledge, and memories. A chat inside it is where I review drafts.
- Memories hold the state. Folders of markdown the agent reads and writes. Plain text, no database.
- Integrations handle the outside world. I connected my X account once. Aisle holds the credentials and refreshes them, so the tasks call
aisle.integrations.xwithout ever holding a token.
The whole thing splits into five jobs. Five markdown docs handle steering. Two scheduled tasks execute. I handle review. A weekly task handles learning. The native X integration handles connectivity.
One constraint shaped everything. The Project agent can read memory docs and create new ones, but it can't modify existing ones. Anything that changes a doc has to run as a task. So the Project chat reasons and proposes while the tasks act.
Forcing every state change through a script I can read turned the restriction into the thing I actually wanted.
The steering docs:
Five markdown docs in a folder called kb. This is the only place I change what the agent does.
- Goals and strategy. Audience growth and credibility in AI automation. The agent never pitches. This doc also fixes the vocabulary so it describes the product correctly.
- Voice and style. How @tessi3r sounds. Direct and first person, skeptical of hype, allergic to filler. It avoids hashtags, emoji, em dashes, and exclamation points. Banned words and patterns, with good and bad examples. The drafting tasks hand this doc to the model as instructions, so voice is the frame the writing happens inside, not a filter applied after.
- Topics and keywords. What's worth posting about, plus the search terms the engagement task uses. The search terms keep the word "workflow" because that's how people describe the problem, even though the posts themselves avoid it.
- Accounts to watch. Who to engage, who to avoid, how to reply.
- Autonomy rules. The limits. Key-value lines for modes, daily caps, quiet hours, and how far the learning loop can go. Every setting has a default, so this doc only carries the lines I want to override.
One more input: the Project's system message, the agent's standing instructions for tone in the review chat. Between the five docs and that, the agent's whole behavior is text I can edit. Change a line and the next run reflects it without a redeploy.
The working memory:
Four more folders hold state and history.
- Review queue. One doc per draft, stamped with my outcome and reason. This is the decision log the learning step reads back.
- Post history. One doc per published item. The agent checks here before committing a new draft so it doesn't repeat itself. It also leaves a marker when a thread is closed to replies, so it stops retrying dead ends.
- Lessons. A single note the agent writes to itself, rewritten weekly. The drafting tasks read it as lower-priority guidance. Steering docs win on conflict.
- Reflection log. One record per weekly run, so I can see what the agent noticed and what it changed.
I turned on semantic search for steering and post history, so the agent searches them by meaning: "have I made a point like this before?" The bookkeeping folders use exact labels, which is faster. Matching the lookup to the folder keeps it cheap and accurate.
Six Tasks:

- Author original posts (every six hours). Reads the steering docs and the lessons note. Writes a batch in voice. Checks each against post history. A second pass ranks them and drops anything that breaks the rules. Strips the banned punctuation automatically. In review mode it sends the top five to the chat. In auto mode it publishes the top one within the cap and quiet hours.
- Engage threads (scheduled). Builds searches from the topics doc, pulls 200 to 300 candidates, then filters hard before spending compute. Drops anything older than 48 hours. Removes threads it's seen. Scores the rest cheaply. Caps at one reply per account per run. Drafts a reply for the top few. X blocks automated replies on our access tier unless the other person already mentioned or quoted us. So the task splits its output. Replies to people who mentioned us post through the API. Replies the task found by searching become "post this manually" drafts with a link, for me to paste in the browser. The agent never forces those through. The restriction doesn't apply to original posts.
- Record decision (runs from the review step). Writes the outcome onto the draft. Posted with the tweet id, or rejected with my reason, which is required. It's a separate task because only a task can modify a memory doc. This is what turns a stack of approvals and rejections into the log the agent learns from.
- Review pending (manual). Pulls every still-pending draft into one chat, newest first, so I can clear the backlog in one sitting.
- Reflect on decisions (weekly). The interesting one, covered below.
- Analyze performance (not built yet). It covers the other half of the loop. Pull engagement metrics and suggest tuning once there's enough history to read.
Two throwaway setup tasks sit outside all this. One verifies the X connection, one reveals the Project id.
The reflection task:
Every other task produces drafts and records what I did with them. This one reads the decisions back and turns them into something the agent can use. It runs weekly and does five things.
- Checks there's enough to learn from. Gathers every decided draft. Fewer than 15, it stops. Reflecting on a handful teaches the agent to overfit to one-off calls.
- Looks at a recent window. Takes the most recent 80 decisions, newest first. A rolling window, because the next step rewrites the lessons from scratch each run. Lessons that stop coming up age out.
- Finds the patterns in one pass. Hands those decisions, with my reasons attached, to a frontier model in one structured request. The instruction is specific: find patterns that recur in at least four decisions, ignore one-offs, decide where each fix belongs, and don't restate rules already in the steering docs. It returns lessons (short directives for next round's drafting, tagged for originals or replies, with a count behind each), steering-doc proposals (concrete edits with the exact line and the evidence), and graduation candidates (topics with a strong record that might be ready to post on their own).
- Splits the output by risk. The lessons get written into the single note, rewritten from scratch each run, capped at twelve bullets. Safe to apply automatically: small, additive, and I can delete it by hand. The proposals are higher stakes. By default the agent doesn't apply them. They go into a review chat for me, and the task saves a copy to the reflection log.
- Climbs the ladder, slowly. One setting controls how far proposals go on their own. proposals is the starting point: suggestions only. safe may add accounts to the avoid list itself, which only ever makes the agent do less, which is the safe way to be wrong. lists may also add topics and accounts to engage.
Two things never graduate, at any setting. Rewriting the voice or goals prose, and marking a topic safe to auto-post. Those stay suggestions I apply by hand.
What I noticed building it:
The split between "agent can read and propose" and "task can modify" felt restrictive when I started. By hour four I'd stopped fighting it. Every state change flows through a script, which means every memory change shows up as a git-visible script run I can read, version, review, and roll back.
Rewriting the lessons note from scratch each week is the decision I went back and forth on most. The alternative is append-only, with the agent crossing out old lessons. Rewriting from scratch is harder to get right and easier to live with. The note stays short, dead lessons age out on their own, and I never clean up an accumulating list.
I expected the "post this manually" workaround to feel embarrassing. It doesn't. The X constraint isn't something I can engineer around, so the agent surfaces it instead of pretending it isn't there. It puts the draft in front of me with a link and I paste it. The seam shows, and I prefer that to having the agent fail without notice or work around the rules in a way that gets the account flagged.
Two weeks in, the decision log is doing more than I expected. The reasons I type into rejections are the actual training data for the reflection task. I notice myself writing shorter rejection notes because I'm repeating the same complaints less. If that holds, it's the closest thing to a real metric I have for whether the loop works.
Where I'm going next:
Whether the reflection task surfaces lessons I'd have written myself. If after four weeks the proposals read like generic writing advice, the window's too narrow or the prompt's too loose. If they read like notes from someone paying close attention to my taste, the loop is doing its job.
Whether my rejection reasons get shorter. If the agent's learning, I should find myself repeating the same reason less, because the drafting tasks already absorbed it. Counting the variety of reasons tells me more than counting the rejects.
Whether the steering docs drift from my voice as the agent contributes to them. It can append to lists but never rewrite voice or goals. I want to read those docs in three months and still recognize them. If I don't, the ladder needs tightening.
Whether I ever graduate a topic to auto-post. The threshold is 15 clean reviews on one topic. Hitting it means the agent produces drafts I accept without edits, which is the only honest definition of trust I've found. Not graduating anything tells me my taste is too varied to pin down, or the agent hasn't earned it yet.
The broader bet is that an agent built this way still works after I've changed my mind about the prompts twice. Most agent demos run clean on day one and collect dead config files by month three.
Day-one performance isn't the test. Whether I'm still using it in six months is, and whether the steering docs by then look like something I wrote or something the agent and I wrote together.
I'll write the follow-up once a few months have passed.
First shared as an article on X. Want to build something like this? Open Aisle →